The idea of data independence is key in database management systems. It shapes how these systems work and grow. It’s important for DBMS flexibility, affecting daily tasks and big plans. But, what is it, and why should we learn about it?
As system architecture gets more complex, being able to change a database without messing up the whole system is crucial. The latest studies, books, and expert talks all show how vital data independence is.
This quick guide will cover the basics of data independence. It will show how it helps in making better DBMS designs. By learning about it, database experts can build systems that can handle the changing needs of today’s world.
Table of Contents
Key Takeaways
- Data independence is key to DBMS flexibility and robust system architecture.
- Grasping data independence is critical for database professionals and students alike.
- Understanding the evolution of DBMS informs modern database design and functionality.
- Latest journals, textbooks, and expert insights are valuable resources for learning about data independence.
- Proper comprehension of data independence facilitates the creation of forward-thinking DBMS solutions.
What is Data Independence in Database Management Systems?
Data independence is key in database management. It’s a big part of DBMS architecture. It’s important for making changes or handling data.
Defining Data Independence
Data independence lets you change a database’s structure without affecting the apps that use it. This makes databases more flexible and easier to grow. It’s a core part of modern DBMS architecture.
Significance in DBMS
Data independence is very important in DBMS. It keeps systems running smoothly when data is changed. It also means changes can be made without hurting the user or database performance. Here are some benefits:
- Enhanced flexibility in handling changes in data structure
- Increased efficiency in DBMS maintenance and scalability
- Improved data security and integrity due to isolated changes
These points show data independence is more than a technical feature. It’s a strategic asset for managing databases, making them strong and flexible.
Types of Data Independence
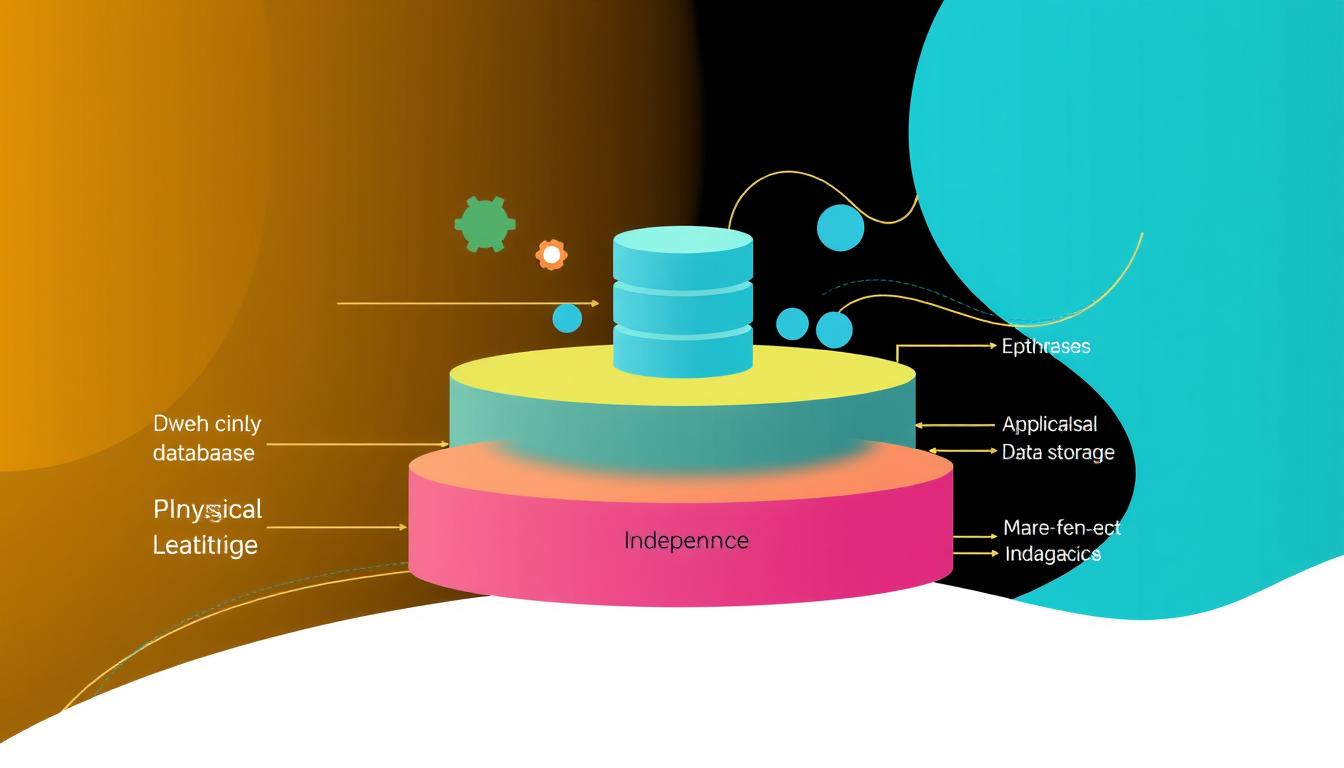
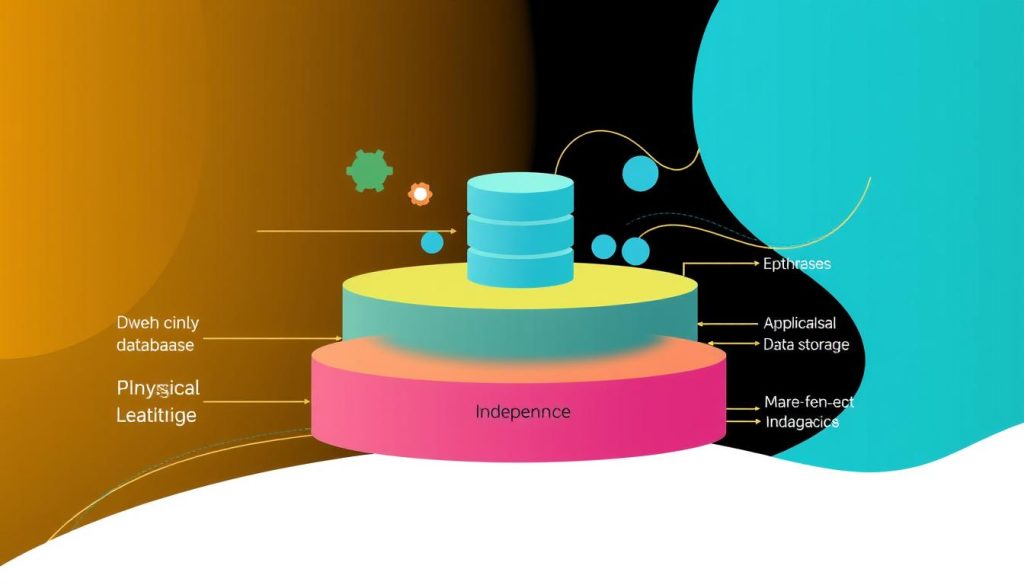
Data independence is key in database management systems. It lets you change the database’s structure without affecting higher levels. There are two main types: logical and physical.
Logical Data Independence Explained
Logical data independence is vital for a database’s flexibility. It lets admins change the database’s structure, like adding new fields, without affecting the data storage. This keeps the database’s changes hidden from users, making updates easier.
- Advantages: It makes it easier to change the data model as needed without affecting apps.
- Examples: Adding a new column to a table or changing an existing column’s type.
Physical Data Independence Explained
Physical data independence means you can change how data is stored without altering the database’s structure. This is crucial for improving database performance and scaling without affecting apps.
- Advantages: It allows for better database performance and cost-effective growth without changing the app’s view.
- Examples: Upgrading to faster storage or changing a database file’s location.
Logical data independence and physical data independence together make databases strong and adaptable. They ensure data layer separation doesn’t slow down app growth or evolution.
The Role of Data Abstraction in Data Independence
Data abstraction layers play a crucial role in data independence in today’s database systems. They help manage complexity by hiding the technical details of data storage and operations. This makes it easier for users to interact with database systems.
Understanding the Layers of Abstraction
Data abstraction in database systems has several layers, each with its own purpose. These layers include:
- Physical Layer: Manages the physical storage of data.
- Logical Layer: Defines the logical structure of data, independent of its physical organization.
- View Layer: Allows users to access data in a form that is tailored to their needs, without revealing the underlying complexities.
Each layer helps keep the user away from the complex database operations. This makes the system user-friendly and secure.
How Abstraction Contributes to Independence
Abstraction is key to achieving data independence in database systems. Here are some benefits:
- Separation from Physical Storage: By abstracting the physical details of data storage, changes to storage mechanisms do not affect application queries or data processing.
- Flexibility in Data Access: Views provided by abstraction allow different users to see data in various ways. This can be optimized for their specific needs without changing the underlying data structure.
- Enhanced Security: With different layers managing different aspects of the database, it’s easier to implement strong security measures. This controls who has access to what data and how they can interact with it.
The strategic use of data abstraction layers creates a more robust, flexible, and manageable database environment. This segregation supports the core goals of data independence. It meets the needs of data management in large and complex database systems.
Challenges of Implementing Data Independence
The idea of keeping data independent is key in Database Management Systems (DBMS). Yet, database implementation challenges and DBMS limitations often face organizations.

One big problem is integrating with old systems. This takes a lot of time and money. Trying to make these systems support data independence is hard and expensive.
- Technical complexities: Adding new features to old systems is very detailed. This makes the process slow.
- Cost implications: New technologies and training cost a lot at first.
- Staff retraining: Old systems need staff to learn new things. This makes the transition longer.
Even with the best DBMS, DBMS limitations can still affect performance. These issues often involve scalability and security. They make it hard to keep data independent.
But, there are ways to deal with these problems. For example, gradual integration and using middleware can help. They make it easier to connect old systems with new ones. This reduces costs and impacts on daily work.
In summary, achieving full data independence in DBMS is tough. But, with careful planning and the right technology, it’s possible. This approach improves how well an organization works. It also makes data safer and more accessible.
Data Independence in DBMS
Database management systems have grown, making data independence key. It adds flexibility and efficiency in data handling. This section explores its development and practical use.
Historical Development and Evolution
Data independence is crucial in database history. The term database evolution shows how systems have grown. They now handle complex data types better, keeping information safe and easy to access.
Over the years, DBMS software and strategies have improved. This is due to growing needs for dynamic data interaction.
Theoretical vs. Practical Aspects
In theory, data independence separates data from its use. This lets systems manage data without changing applications. But, practical data independence faces real-world challenges.
There’s a gap between theory and practice. Integrating old systems and adapting to new tech can be hard. This makes it tough to fully apply the theory.
- Comparing theory with practice shows differences. These affect how we choose systems and handle data.
- Talking to experts helps find ways to bridge the gap. They share how to make theory work in real life.
These points highlight the need for strategies that match theory with practice.
Impact of Data Independence on Database Design
Data independence is key in database management. It affects database design principles, efficient DBMS design, and design optimization. Knowing its impact is vital for those planning and running databases.

Data independence means changes in one part shouldn’t mess with others. This idea shapes how we design databases today. For example, it helps systems adjust to user needs without changing how data is stored.
- Logical Data Independence: This lets designers change schemas without affecting programs or storage. It’s key for long-term design optimization.
- Physical Data Independence: It allows changes in storage that don’t touch how users see data. This boosts efficient DBMS design.
Data independence is crucial for flexible and scalable database design. It helps systems meet current needs and grow with new technologies.
Looking at design optimization, data independence helps us plan for the future. It makes sure databases can handle changes without needing a full redesign. This makes database systems more efficient and follows best practices in database projects.
- Start by adding data independence early in design to ensure systems can grow and adapt.
- Use flexible schema patterns to make data easier to query and manage, without worrying about storage details.
By using data independence in database design, businesses can save on costs. They avoid downtime and big redesigns, leading to a stronger and more flexible IT setup.
Advantages of Data Independence in DBMS
Data independence is key in making database management systems (DBMS) better. It boosts system adaptability and operational efficiency. It also makes databases scalable and strong, perfect for changing business needs.
Operational efficiency in DBMS gets a big boost from data independence. It means you don’t have to change the database much when you update the application. This cuts down on downtime and boosts productivity, helping businesses adapt fast to market changes.
- System scalability: As businesses grow, so do their data needs. Data independence makes it easy to scale databases, growing them without hurting current operations or performance.
- Adaptability in DBMS: In today’s fast-changing tech world, being adaptable is crucial. Data independence lets you change the database without touching the front-end apps. This makes it easy to keep up with new tech and processes.
Data independence makes operations smoother and supports business strategies with a stable yet flexible setup. Studies and real-world examples show big improvements in performance and capacity in systems with high data independence.
By embracing data independence, organizations can gain a competitive edge. Their database systems will be efficient, scalable, and strong enough to quickly adapt to changes.
Understanding Schema and their Importance
The database schema design is like a blueprint for a database. It helps make sure databases work well and are easy to use. Knowing about logical and physical schemas is key for keeping data separate from how it’s used.
Logical Schema and Data Independence
The logical schema shows how a database is set up from the DBMS’s view. It tells us how data is stored and accessed. Keeping this schema consistent is important for data independence.
This means changes can be made without affecting users. It’s essential for making changes without stopping services or needing a lot of downtime.
Physical Schema and Data Independence
The physical schema deals with where data is stored. It includes the devices and methods for storing and retrieving data efficiently. Changes to this schema can be made without affecting the logical schema or applications.
This keeps the system’s visible parts safe from changes made behind the scenes. It’s crucial for keeping the database running smoothly.
Database experts work hard to understand both logical and physical schema concepts. They aim to create systems that are strong and reliable. Knowing how to design schemas is vital for a database’s success and future-proofing.
FAQ
What is Data Independence in Database Management Systems (DBMS)?
Data independence in DBMS means you can change the database structure without affecting how people use it. It lets you update the database without needing to change everything else.
How does Data Independence contribute to DBMS flexibility?
It makes the database more flexible. Database admins can change the database structure without affecting the apps that use it. This makes it easier to keep the database up to date.
Can you explain Logical Data Independence?
Logical data independence lets you change the database structure without affecting how users see it. It’s about changing how data is organized without changing how it’s used.
What is Physical Data Independence and why is it important?
Physical data independence lets you change how data is stored without affecting its structure or use. It’s key for improving performance and making changes without disrupting the system.
What role does Data Abstraction play in Data Independence?
Data abstraction creates layers that separate the database from user apps. This makes it easier to change the database without affecting users. It helps keep the database independent and stable.
What are common challenges in implementing Data Independence?
Challenges include dealing with old systems, costs, and technical issues. It often requires a big effort to reorganize databases for independence, which can be costly and complex.
How has Data Independence evolved in Database Management?
Data independence has grown a lot since the start of database systems. Early systems were hard to change. Now, thanks to new technologies, systems are more flexible and adaptable.
What impact does Data Independence have on Database Design?
It shapes database design to be flexible and modular. It means thinking about future needs and making databases that can grow and change with them.
What are the practical advantages of achieving Data Independence in a DBMS?
It brings many benefits like better efficiency, scalability, and protection against data loss. It makes updates easier and helps everyone involved in database management.
How do Logical and Physical Schemas relate to Data Independence in DBMS?
Logical schemas are how users see the data, while physical schemas are how it’s stored. Data independence ensures changes in one don’t affect the other, keeping the system running smoothly.