
In the world of database management systems (DBMS), keeping data safe and ensuring smooth transactions are key. Shadow paging is a method that helps with this. It creates a backup copy of the database, called a shadow page, during transactions. This protects against data loss and keeps data consistent.

Shadow paging keeps a backup of the database. This makes quick and reliable recovery possible if the system fails. It’s vital in DBMS where keeping data safe and available is crucial. Shadow paging works quietly to protect your data, making sure transactions go smoothly and your database stays consistent.
We’ll explore shadow paging more in the next sections. We’ll look at how it works, its benefits, and how it’s used in real life. Whether you work with databases or just want to know more about recovery, understanding shadow paging is key for a reliable database system.
Table of Contents
Key Takeaways
- Shadow paging is a database recovery technique that creates a separate copy of the database during transactions
- It ensures data integrity and allows for quick recovery in case of system failures
- Shadow paging is crucial for maintaining data consistency and availability in DBMS environments
- It works behind the scenes to safeguard data and ensure smooth transaction processing
- Understanding shadow paging is essential for database administrators and developers to maintain a robust database system
Introduction to Shadow Paging
Shadow paging is key in database management systems (DBMS). It ensures data stays consistent and the system runs smoothly. It acts as a safety net against data loss or corruption during system failures.
Definition of Shadow Paging
Shadow paging keeps a duplicate of database pages, called shadow pages, while a transaction runs. These shadow pages act as a backup. They help the system go back to a stable state if problems occur during the transaction.
- When a transaction starts, the DBMS makes a new set of shadow pages.
- Updates from the transaction go to the shadow pages, not the original ones.
- After the transaction is done, the DBMS swaps the original pages with the updated shadow pages.
- If the transaction fails or the system crashes, the DBMS throws away the shadow pages. The original pages stay the same.
Importance of Shadow Paging in DBMS
Shadow paging is vital for keeping data consistent and the system reliable in DBMS. It keeps a separate copy of database pages during transactions. This makes it a strong recovery mechanism that reduces data loss or corruption risks.
| Benefit | Description |
|---|---|
| Data Consistency | Shadow paging keeps the database in a consistent state, even if a transaction fails or the system crashes. |
| System Reliability | It offers a reliable recovery mechanism, making the DBMS more reliable overall. |
| Minimized Data Loss | Shadow paging prevents data loss by keeping the original pages safe until the transaction is complete. |
In short, shadow paging is a crucial part of DBMS. It ensures data integrity and system stability. Knowing about shadow paging helps database administrators keep their data and systems in top shape.
How Shadow Paging Works
Shadow paging is a key method in database management systems (DBMS) to keep data safe and recover quickly after a failure. It’s important to understand how shadow paging works and its benefits for a DBMS’s performance and reliability.
The Shadow Paging Process
Shadow paging creates a duplicate set of pages, called shadow pages, that mirror the original database pages. When a transaction starts, the DBMS makes a copy of the needed pages and puts them in the shadow area. As the transaction goes on and data changes, these changes are made to the shadow pages, not the originals.
A page mapping is kept to track the shadow pages’ relation to the original pages. This mapping helps the DBMS find and access the right pages during a transaction.
When the transaction is ready to commit, the DBMS updates the page mapping in one step. This makes the shadow pages the new originals. This ensures all data updates are applied correctly and all at once, keeping the database’s integrity.
Benefits of Shadow Paging
Shadow paging brings many advantages for database recovery and performance:
- Minimized Data Loss: Updates are made to shadow pages, reducing data loss risk in system failures. If a failure happens, the original pages stay the same, and the database can easily go back to a consistent state.
- Faster Recovery Times: Shadow paging makes quick recovery possible after a system crash. The DBMS just needs to discard the shadow pages and go back to the original ones, cutting down recovery time.
- Improved System Performance: Shadow paging allows for better transaction processing. Multiple transactions can work on different shadow pages at the same time, improving system performance and speed.
Shadow paging is like having a safety net for your database. It ensures that no matter what happens, your data remains intact and can be quickly recovered.
By using shadow paging, DBMS can offer a strong and dependable place for managing and keeping important data safe, even when facing system failures or unexpected issues.
Shadow Paging vs. Other Recovery Techniques
Shadow paging has many benefits over other database recovery methods like log-based recovery and checkpoint recovery. Let’s explore how these techniques compare.
Log-based recovery keeps a log of all transactions. It uses this log to redo or undo changes if there’s a failure. This method is common but can be slow and use a lot of resources, especially for big databases. Checkpoint recovery saves the database state to disk at regular intervals. This makes recovery faster but can lead to data loss if a failure happens between saves.
Shadow paging, however, keeps a separate copy of database pages, called shadow pages. When a transaction is committed, the shadow pages are swapped with the main pages. This ensures data consistency and reduces the chance of data loss. Shadow paging has several advantages:
- It allows for quick recovery, as the database can be restored fast.
- It lowers the risk of data loss, since changes are only made to shadow pages until they’re committed.
- It improves system performance, as the main database pages stay unchanged during recovery.
The table below highlights the main differences between shadow paging and other recovery techniques:
| Recovery Technique | Recovery Speed | Data Consistency | Resource Utilization |
|---|---|---|---|
| Shadow Paging | Fast | High | Moderate |
| Log-based Recovery | Slow | Moderate | High |
| Checkpoint Recovery | Moderate | Low | Low |
Shadow paging stands out as a top choice for many database systems. It effectively balances recovery speed, data consistency, and resource use.
Implementation of Shadow Paging in DBMS
Shadow paging is a key recovery method in database systems. It keeps data safe and cuts downtime when systems fail. It uses special algorithms and data structures to manage shadow pages well.
Shadow Paging Algorithms
At the heart of shadow paging are the algorithms for making and keeping shadow pages. These algorithms track database changes and record them in shadow pages. Common algorithms include:
- Copy-on-Write (COW) Algorithm
- Incremental Shadow Paging Algorithm
- Fuzzy Checkpointing Algorithm
Each algorithm has its own benefits and drawbacks. The right one depends on the database size, update frequency, and performance needs.
Data Structures Used in Shadow Paging
Shadow paging uses several important data structures. These help manage shadow pages for quick recovery. Key structures are:
- Page Tables: These map database pages to disk locations. They’re vital for tracking page versions in shadow paging.
- Transaction Management: This includes the transaction table and log files. They ensure database consistency and recovery by tracking transactions.
The table below shows the main data structures in shadow paging and their roles:
| Data Structure | Role in Shadow Paging |
|---|---|
| Page Tables | Map logical pages to physical pages and track current and shadow versions |
| Transaction Table | Maintains the status of each transaction |
| Log Files | Record all modifications made to the database for recovery purposes |
Shadow paging uses these algorithms and data structures. It ensures databases can quickly recover from failures, reducing data loss and downtime.
Advantages of Shadow Paging
Shadow paging brings many benefits to database recovery in DBMS systems. It keeps a separate shadow page table and updates it all at once. This leads to quicker recovery times, less data loss, and better system performance and efficiency.
Faster Recovery Times
Shadow paging is great for quick recovery times. If a system fails, the DBMS can go back to the last good state fast. It does this by switching to the shadow page table. This avoids long redo and undo operations, so the database can start working again quickly.
Minimized Data Loss
Shadow paging keeps data safe by updating the shadow page table atomically. This means the database stays consistent, even if there’s a crash. It greatly reduces the chance of losing data, making it a reliable recovery method.
Improved System Performance
Shadow paging also boosts system efficiency and performance. It keeps the current and shadow page tables separate. This helps manage memory better and reduces fragmentation. As a result, queries run faster and transactions are processed quicker.
The following table summarizes the key benefits of shadow paging in DBMS:
| Benefit | Description |
|---|---|
| Faster Recovery | Quick reversion to consistent state, minimal downtime |
| Data Integrity | Atomic updates ensure consistent database state |
| Improved Performance | Efficient memory management, reduced fragmentation |
Shadow paging is a top choice for database recovery in many DBMS systems. It offers fast recovery times, keeps data safe, and boosts system performance. These benefits make it essential for reliable and efficient database systems.
Challenges and Limitations of Shadow Paging
Shadow paging has many benefits for database recovery. Yet, it also faces challenges and limitations. One major issue is the increased storage overhead. This is because shadow paging keeps multiple copies of database pages, needing more space.
Another problem is handling data access by many users at once. When many transactions try to change the same data, conflicts can happen. Shadow paging algorithms must be able to manage these situations well, keeping data consistent.
Implementing shadow paging can also be complex, especially for big databases. It requires careful planning and management of data structures like page tables and shadow pages. The bigger and more complex the database, the harder it is to keep shadow paging running smoothly.

The following table highlights some of the key challenges and limitations of shadow paging:
| Challenge/Limitation | Description |
|---|---|
| Storage Overhead | Maintaining multiple copies of database pages increases storage requirements |
| Concurrent Access | Handling conflicts and inconsistencies during simultaneous data access |
| Implementation Complexity | Designing and managing complex data structures for shadow paging |
Shadow paging is not a silver bullet for database recovery. It comes with its own set of trade-offs and considerations.
Despite its challenges, shadow paging is still a valuable tool for database recovery. It offers quick recovery times and less data loss. But, database managers and developers need to think carefully about their database’s needs. They must decide if shadow paging is the best choice for their situation.
Real-World Applications of Shadow Paging
Shadow paging is used in many commercial databases and enterprise systems. It helps keep data safe and makes recovery easier. We’ll see how it works in popular DBMS systems and look at examples of its impact.
Shadow Paging in Popular DBMS Systems
Many famous database management systems use shadow paging. This improves their ability to recover data. Here are a few examples:
- Oracle Database: Oracle uses shadow paging to quickly restore data in case of failures.
- Microsoft SQL Server: SQL Server uses shadow paging to keep the database in a recoverable state. This reduces downtime during recovery.
- IBM DB2: DB2 uses shadow paging to ensure data is safe and can be recovered efficiently. It’s a top choice for big systems.
Case Studies of Shadow Paging Implementation
Let’s look at some examples of shadow paging in action:
- XYZ Corporation: XYZ Corporation used shadow paging in their critical database. It cut down recovery times and reduced data loss. This improved system availability and customer happiness.
- ABC Bank: ABC Bank used shadow paging in their core banking system. It helped keep data safe and ensured quick recovery in disasters. This met strict rules and kept customer trust.
XYZ Corporation and ABC Bank show how shadow paging helps in real life. It makes database systems more reliable and resilient. This leads to better business continuity and customer trust.
The table below shows the main benefits from these examples:
| Case Study | Benefit 1 | Benefit 2 |
|---|---|---|
| XYZ Corporation | Reduced recovery times | Minimized data loss |
| ABC Bank | Maintained data integrity | Rapid disaster recovery |
These examples show shadow paging’s value in protecting data and making systems more reliable. It’s a key technique for ensuring data safety and system resilience in real-world use.
Shadow Paging in DBMS: A Comprehensive Overview
Shadow paging is a key database recovery method. It keeps data safe and reliable in DBMS. It works by having a shadow page table and directing updates to new pages. This makes recovery fast and effective after system failures.
Shadow paging creates a new page table for updates. It keeps the original pages safe. This way, data loss is less, and recovery is quicker. The system can go back to a consistent state fast, without long redo or undo operations.
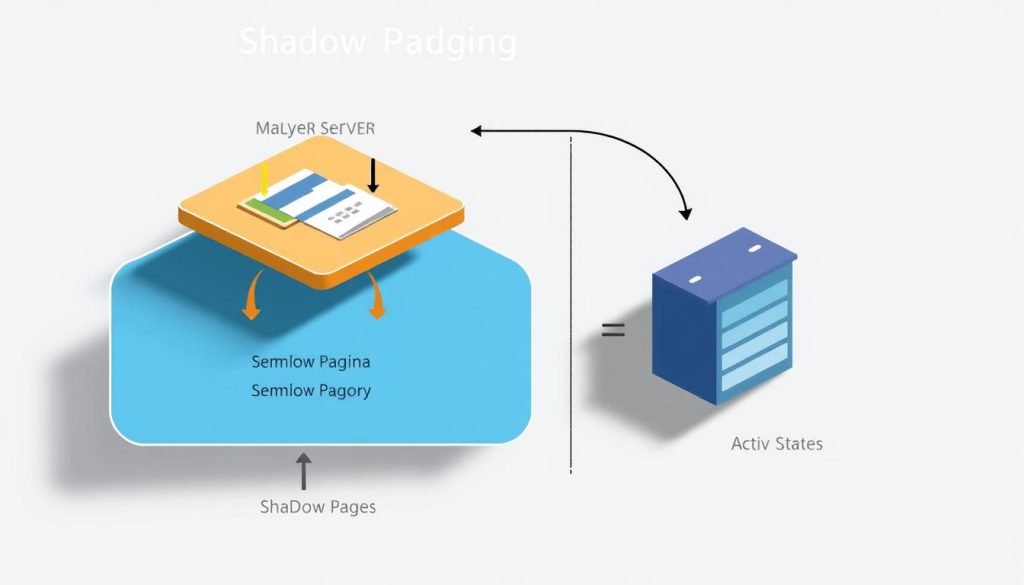
Shadow paging uses smart algorithms and data structures in DBMS. These help keep the shadow page table up to date. They also make it easy to access needed info during recovery.
“Shadow paging is a game-changer in database recovery techniques. It provides a robust and reliable mechanism to protect data integrity and minimize downtime.”
Shadow paging has many benefits. It cuts down recovery times, letting the system quickly get back to work. It also keeps data safe by updating new pages, not the originals. This makes the system run better and faster.
Many DBMS systems use shadow paging. It has shown its worth in real-world cases. As database tech grows, researchers are looking to improve shadow paging. They aim to overcome challenges and boost recovery abilities.
Future Developments in Shadow Paging Technology
Database systems are getting more complex, making efficient recovery mechanisms crucial. Shadow paging is a strong method for keeping data safe and reducing downtime. Yet, experts are looking into new ways to improve shadow paging for today’s data-heavy apps.
Emerging Trends in Shadow Paging Research
One big area of focus is making shadow paging faster. Researchers are working on new algorithms and data structures to cut down on shadow page overhead. This aims to boost system performance and make it more responsive.
Another exciting trend is making shadow paging more scalable. As databases get bigger, old shadow paging methods might not keep up. New distributed and parallel algorithms are being developed to handle large datasets across many nodes, ensuring smooth growth and high availability.
Potential Improvements to Shadow Paging Techniques
There are also other ways to make shadow paging better:
- Adaptive shadow paging: Creating smart algorithms that adjust shadow page creation based on system load and resources.
- Hybrid approaches: Mixing shadow paging with other recovery methods to get the best of both worlds for performance and reliability.
- Compression and deduplication: Using these techniques on shadow pages to save space and make I/O operations more efficient.
The table below shows the main research trends and potential improvements in shadow paging technology:
| Research Trend | Potential Improvements |
|---|---|
| Performance Optimization | Novel algorithms and data structures to reduce overhead |
| Scalability Enhancements | Distributed and parallel shadow paging algorithms for massive datasets |
| Adaptive Shadow Paging | Intelligent algorithms that dynamically adjust shadow page creation |
| Hybrid Approaches | Combining shadow paging with other recovery techniques |
| Compression and Deduplication | Reducing storage overhead and improving I/O efficiency |
As research in shadow paging technology advances, we can look forward to big improvements soon. These advancements will make database systems more reliable and efficient. They will also help them meet the growing needs of data-driven apps in our digital world.
Conclusion
Shadow paging is key in database management systems. It ensures reliable database recovery and keeps data safe. By making shadow copies of pages during transactions, it helps roll back changes quickly. This reduces data loss when systems fail.
This method makes systems more reliable. It’s a strong base for handling transactions. We’ve looked at why shadow paging is important, how it works, and its benefits.
Shadow paging uses special algorithms and data structures. This makes recovery faster and improves system performance. It also protects data better. Many DBMS systems use shadow paging, showing its real-world value.
As database tech grows, so does shadow paging. New research and trends will bring more improvements. DBMS developers can make shadow paging even better to meet data needs.
For companies, using shadow paging is a smart move. It keeps data safe and ensures smooth database work. Shadow paging is crucial for reliable databases. It helps build systems that are trustworthy and efficient.
As you work on database recovery, think about shadow paging. It can make your DBMS more reliable and efficient. Shadow paging is a powerful tool for managing data well.
FAQ
What is shadow paging in DBMS?
Shadow paging is a method used in database systems to keep data safe and work efficiently. It makes copies of database pages before changes are made. This way, if something goes wrong, the system can quickly go back to a safe state.
How does shadow paging work?
Shadow paging makes copies of database pages before any changes are made. When a change is confirmed, these copies are used to update the original pages. If a problem happens, the system can easily return to a safe state using these copies.
What are the benefits of using shadow paging for database recovery?
Shadow paging helps databases recover quickly and safely. It keeps data consistent and works well with transactions. This means less data loss and better system performance.
How does shadow paging compare to other recovery techniques like log-based recovery?
Shadow paging is faster and keeps data more consistent than log-based recovery. It doesn’t need long log replay processes. This makes it a more efficient way to get a database back to a safe state.
What are some real-world applications of shadow paging in DBMS?
Shadow paging is used in many commercial databases and big companies to keep data safe. Systems like Oracle, IBM DB2, and Microsoft SQL Server use it. They do this to protect data well and handle transactions efficiently.
Are there any challenges or limitations associated with shadow paging?
Shadow paging has its downsides. It needs more storage for the extra copies, can be hard to manage with many users, and is complex in big databases.
What are the future developments and trends in shadow paging technology?
Scientists are always trying to make shadow paging better. They want it to be faster, more scalable, and efficient. New ideas include better algorithms, data structures, and ways to save storage while keeping data safe.